مشاوره
رایگان
Skip to content
دایکه
گروه داده کاوی دایکه – آکادمی علوم داده
Menu and widgets
دانشمند داده
دورهها
پروفایل آموزشی
حساب من
سبد خرید
دیتاها چگونه پزشکی دقیق را متحول می کنند؟
نشریه
دیتاها چگونه پزشکی دقیق را متحول می کنند؟
چگونه هوش مصنوعی میتواند به کشف دارو کمک کند؟
توالی ژنوم انسان و دردسرهای بیگ دیتا
چگونه علم داده، ژنومیک را در صنعت داروسازی هدایت میکند؟
کاربرد علم داده در ژنتیک و ژنومیک؛ بخش 2
کاربرد علم داده در ژنتیک و ژنومیک بخش 1
مدیریت داده های ژنومی
نجوم و ژنومیک؛ 2 غول بیگ دیتا
داده های ژنومی
هوش مصنوعی، یادگیری ماشین و ژنتیک
دیتا ساینس در علم ژنتیک
کاربردهای بیگ دیتا در علم نجوم؛ بخش 2
کاربردهای بیگ دیتا در علم نجوم؛ بخش 1
کشف سیارات فراخورشیدی با هوش مصنوعی
سفرهای فضایی طولانی مدت و سلامت روان فضانوردان؛ آیا هوش مصنوعی میتواند کمککننده باشد؟
پیشرانه یکپارچه موشک با هوش مصنوعی: پیشرفتها و برنامهها
کشاورزی فضایی مبتنی بر هوش مصنوعی
نقش مهم یادگیری ماشین در کاوش جهان
تمرکز هوش مصنوعی برای یافتن سیارات فراخورشیدی
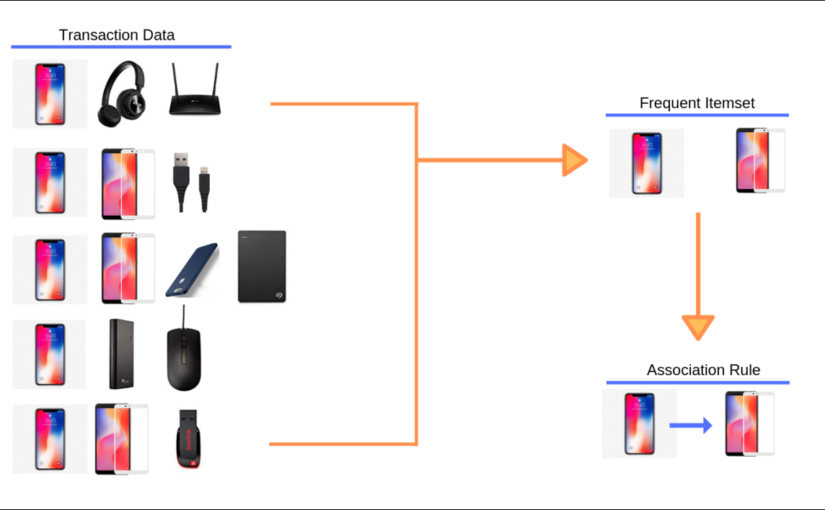
پیاده سازی قوانین انجمنی در نرم افزار
معرفی الگوریتم Apriori
مقدمه ای بر قوانین انجمنی و بیان 2 گام اصلی در شناسایی الگوها
ارزیابی خوشه بندی؛ معرفی 4 معیار
الگوریتم DBScan
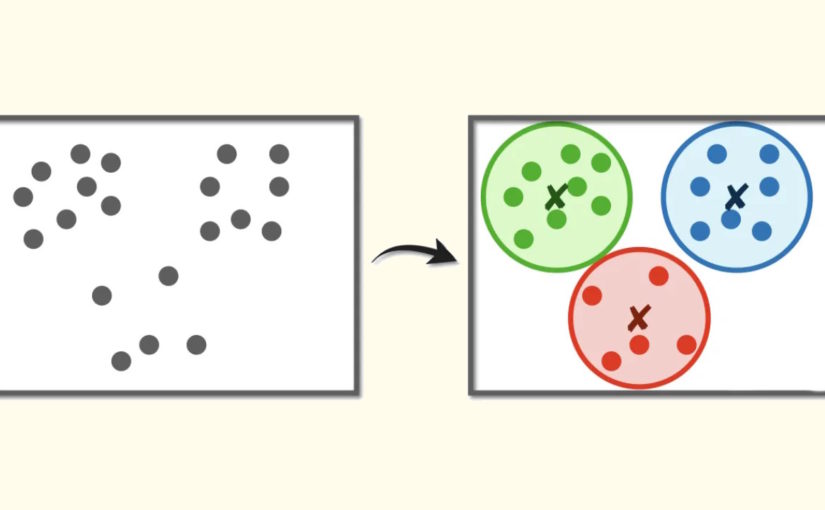
الگوریتم K-Means
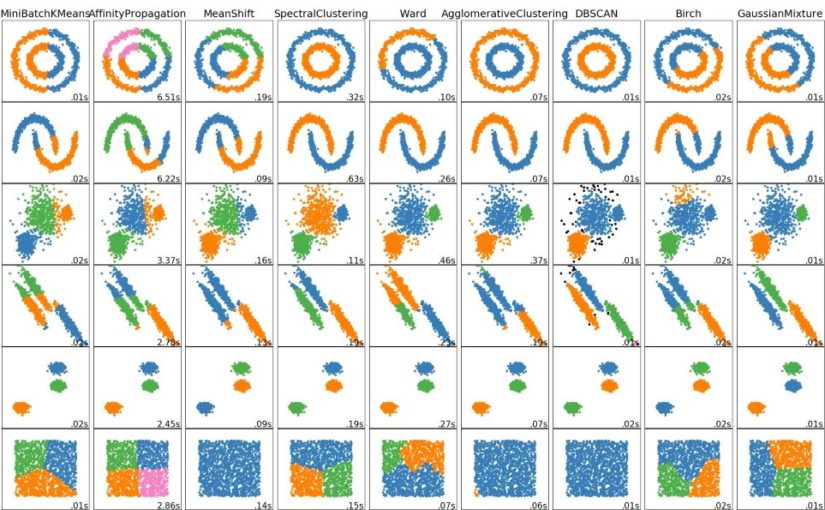
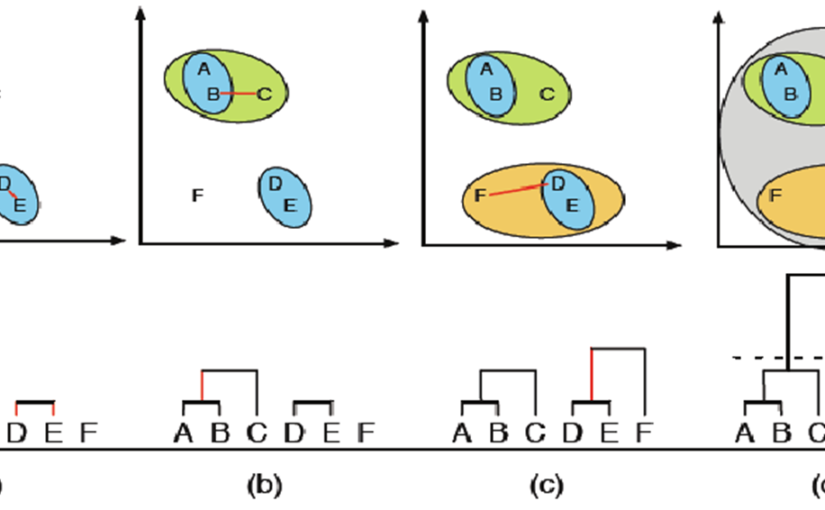
خوشه بندی سلسله مراتبی و بیان 4 رویکرد
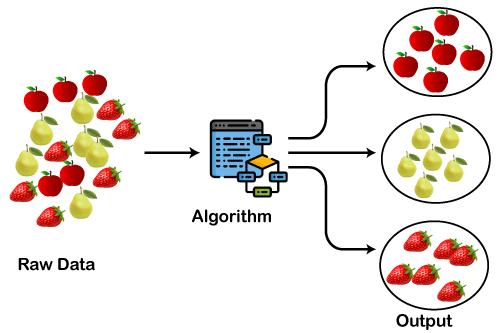
معرفی تکنیک خوشه بندی و بیان 2 حالت کلی
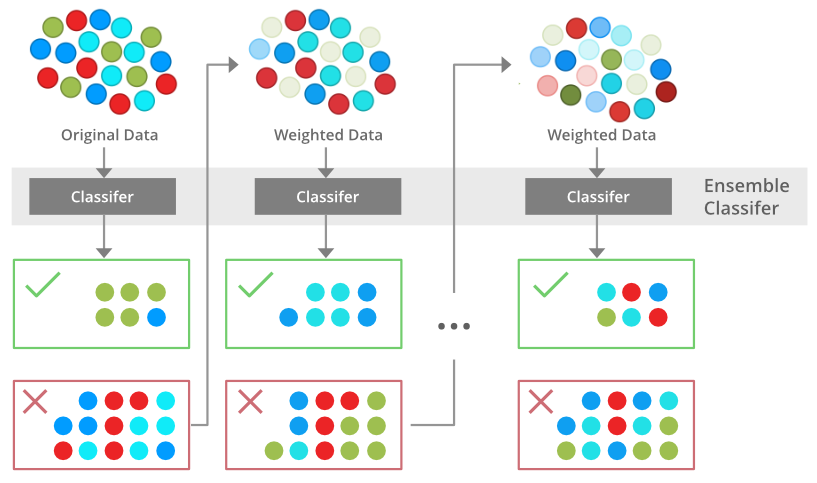
رویکرد Boosting
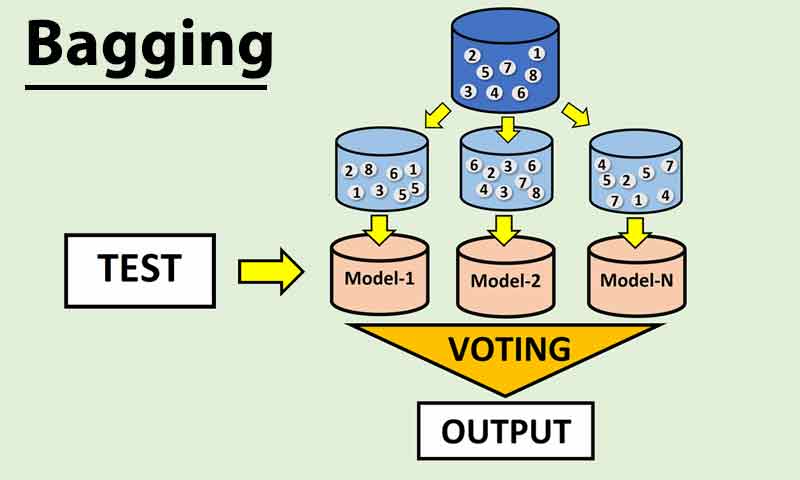
Bagging در یادگیری گروهی
رویکرد Stacking در یادگیری گروهی