
انتخاب مدل
 این بخش از سری مقالات تحلیل بازاریابیِ خردهفروشی دایکه ، ادامهی مثال مطالعهی موردی خردهفروشی تحلیلهای بازاریابی و کمپین است. در دو بخش قبلی، دو الگوریتم درخت تصمیم (CART و C4.5) برای دستهبندی را مطرح کردیم. مثال مطالعهی موردی قبلیِ راجع به بانکداری و مدیریت خطر را به یاد آورید که در آن رگرسیون لجستیک، رویکرد دیگری برای حل مسائل دستهبندی را بحث کردیم. بهعلاوه، چندین الگوریتم یادگیری ماشین و آماری دیگری هم هست که برای کارهای دستهبندی، مثل موارد ذکرشده در زیر، هماناندازه پرقدرتند:
این بخش از سری مقالات تحلیل بازاریابیِ خردهفروشی دایکه ، ادامهی مثال مطالعهی موردی خردهفروشی تحلیلهای بازاریابی و کمپین است. در دو بخش قبلی، دو الگوریتم درخت تصمیم (CART و C4.5) برای دستهبندی را مطرح کردیم. مثال مطالعهی موردی قبلیِ راجع به بانکداری و مدیریت خطر را به یاد آورید که در آن رگرسیون لجستیک، رویکرد دیگری برای حل مسائل دستهبندی را بحث کردیم. بهعلاوه، چندین الگوریتم یادگیری ماشین و آماری دیگری هم هست که برای کارهای دستهبندی، مثل موارد ذکرشده در زیر، هماناندازه پرقدرتند:
- ماشینهای بردار پشتیبان[1]
- جنگل تصادفی[2]
- شبکههای عصبی مصنوعی
- تحلیل تشخیصی
- مدل تجمیعی boosting
- دستهبندی بیز ساده[3]
این لیست کامل نیست، اما شامل برخی از رویکردهای رایج است. کلیهی این رویکردها را در مقالات بعدی دایکه مطرح میکنیم. حالا سؤال این است: چرا تعداد زیادی رویکرد مختلف برای حل مسئلهای مشابه وجود دارد؟ سؤال مهمتری که هرکسی میپرسد این است: کدامیک از این رویکردها بهترین است؟ پاسخ سؤال دوم هیچکدام است! بله، بهترین رویکرد به نوع دادههایی که با آنها کار میکنید بستگی دارد و از آنجاییکه دادهها در هر شکل و اندازهای موجودند، پس نمیتوانید یک بهترین رویکرد برای همهی مسائل داشته باشید. بنابراین، توسعهی مدلهایی با رویکردهای مختلف و انتخاب بهترین مدل برای دادههای شما تمرین مهمی در علم داده و تحلیل است. در این مقاله، در مورد عوامل تأثیرگذار روی فرایند انتخاب مدل بحث میکنیم. هرچند، پیش از شروع بحث اجازه دهید سریعاً برخی از کارهایی که دانشمندان داده انجام میدهند را بررسی کنیم؛ زمانیکه وارد بخشهای بعدی این مثال مطالعهی موردی خواهیم شد، این موضوع به دردمان میخورد.
وظایف علم داده
اساساً وظایفی که دانشمندان داده انجام میدهند را میتوان به شش دستهی گسترده (همانطور که در زیر ارائه شده است) گروهبندی کرد. لطفاً توجه کنید که حتی وظایف علم دادهی مدرن، مثل تحلیلهای وب و رسانههای اجتماعی، متنکاوی، تحلیلهای تصویری و شناسایی الگوی صوت از این شش دستهی گسترده استفاده کردهاند.
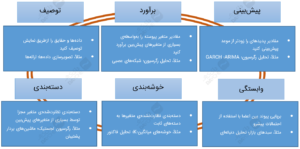 وظایف علم داده
وظایف علم داده
همانطور که متوجه شدید، در این مطالعهی موردی، تا اینجا ۳ وظیفه از لیست بالا، یعنی «توصیف» (تحلیل کاوشگرانهی دادهها)، «وابستگی» (تحلیل وابستگی) و «دستهبندی» (درختهای تصمیم؛ CART و C4.5) را انجام دادیم. EDA تمرین بسیار مهمیست که مدلهای پیشگویانهای در جهت درست استخراج میکند.
در بخشهای پایانی این مطالعهی موردی، چندین «برآورد» انجام میدهیم (یعنی تحلیل رگرسیون برای برآورد درآمد تولیدشده توسط مشتریان ازطریق کمپینها). اجازه دهید برای رسیدگی مسئلهی طبقهبندیمان به انتخاب مدل برگردیم.
انتخاب مدل – مثال مطالعهی موردی خردهفروشی
به مثال مطالعهی موردی خردهفروشیمان برمیگردیم؛ در این مثال، شما مدیر ارشد تحلیل و رئیس راهبرد کسبوکار فروشگاه آنلاینی بهنام درساسمارت هستید که در عرضهی پوشاک تخصص دارد. ازطریق تحلیل کاوشگرانهی دقیق دادهها، چندین عامل که نقش حیاتیای در واکنش مشتریان به کمپین بازاریابی ایفا میکنند را پیدا میکنید؛ برخی از این فاکتورها عبارتند از:
- تازگی: # بازدیدها و خریدهای اخیر از وبسایت شرکت
- توالی خریدها: تأخیر زمانی بین خریدها در ۶ ماه گذشته
- روش پرداخت بهکاررفته: پرداخت نقدی هنگام تحویل، پرداخت با کارت اعتباری، بانکداری اینترنتی و غیره
- دادههای بازاریابی گردآوری شده: گروهبندی برمبنای سبک زندگی (یعنی، دوستداران کالاهای لوکس، سالخوردگان طرفدار کالاهای بسیار گرانقیمت و مزدبگیران دائمی).
- روند مخارج سال گذشته: مقدار پول خرجشده در سال گذشته
- الگوی کاربرد کوپن توسط مشتری
شما مدلهای چندمتغیرهی فوق (یعنی رگرسیون لجستیک، SVM، درختهای تصمیم و غیره) را برای مدلسازی رفتار مشتریان و تولید امتیازات تمایل به خرید امتحان کردهاید. انتخاب مدل درست به دو عامل زیر بستگی دارد:
۱. قدرت پیشگویانهی مدلها
۲. یکپارچگی عملیاتها و کسبوکار
۱. قدرت پیشگویانهی مدلها
عامل اول در انتخاب مدل، قدرت پیشگویانهی کلی مدل موردنظر در مقایسه با سایر مدلها است. برای این مسئلهی دستهبندی، ناحیهی زیر منحنی عملیاتی گیرنده ([4] AUROC) احتمالاً بهترین روش برای ارزیابی قدرت پیشگویانهی مدلها است (راجع به AUROC بیشتر بخوانید). گاهی اوقات از ضریب جینی[5] برای ارزیابی قدرت پیشگویانهی مدلها استفاده میشود؛ جینی نوع دیگری از AUROC است و از لحاظ ریاضی بهصورت زیر بیان میشود:![]()
در نمودار زیر، AUROC برای شبکههای عصبی مصنوعی، رگرسیون لجستیک و درخت تصمیم CART نمایش داده شده است. توجه داشته باشید که در اینجا قدرت پیشگویانهی منحنی مدل کامل (به رنگ سبز)، ۱۰۰ درصد است و مدل تصادفی (به رنگ قرمز) پیشگویی را ازطریق پرتاب سکه نمایش میدهد. مقادیر AUROC نمونهی آزمایشی این سه مدل عبارتند از:
|
مدل |
AUROC |
|
درخت تصمیم |
۷۲٪ |
|
رگرسیون لجستیک |
۷۶٪ |
| شبکههای عصبی مصنوعی |
۷۷٪ |
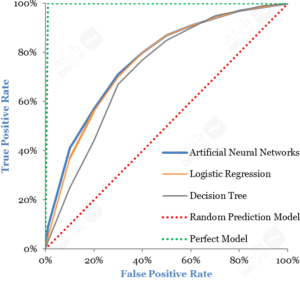 ناحیهی زیر ROC برای مدلهای مختلف
ناحیهی زیر ROC برای مدلهای مختلف
در اینجا، درخت تصمیم خیلی پایینتر از مدلهای دیگر اجرا میشود. این موضوع اغلب در درختهای تصمیم دیده میشود، اما هنوز هم بهدلیل راهکارهای ساده و بسیار فهمپذیر خیلی محبوب و سودمندند. شبکههای عصبی مصنوعی در این مورد، با ناحیهی کمی بالاتر زیر ROC، یک درجه بالاتر از رگرسیون لجستیک اجرا میشوند. بنابراین، براساس معیار اول، شبکههای عصبی مصنوعی بهترین مدل را از بین این سه مدل ارائه میدهند.
۲. یکپارچگی عملیاتها و کسبوکار
این جنبه از انتخاب مدل هم به اندازهی عامل بالا، اگر نه بیشتر، مهم است. انتخاب مدل باید برمبنای زایایی[6] مدل برای کاربرد تجاری در بلندمدت صورت گیرد. بهخاطرسپردن عوامل زیر در شروع فرایند مدلسازی مفید است:
۱) دسترسپذیری مستمر دادهها برای کلیهی متغیرهای پیشبین: بسیاری اوقات، مدلها برمبنای متغیرهای پیشبینی توسعه مییابند که دستیابی منظم و مستمر به آنها دشوار است. نگهداشتن چنین متغیرهایی در مدل، حتی اگر روی قدرت پیشگویانهی بالا نیز تأثیرگذار باشند، توصیه نمیشود. این موضوع مخصوصاً راجع به دادههای شخص ثالث که هر از گاهی خریداری میشوند واقعیت دارد.
۲) مدل باید به اندازهی کافی برای کالیبرهکردن ساده باشد: هدف هر مدلی یکپارچهشدن خوب با سیستمهای IT بهکاررفته توسط کاربران کسبوکار است. تحلیلگران باید زایایی مدل برای یکپارچهسازی فرایند کسبوکار در شروع پروژه را لحاظ کنند تا از دوبارهکاری غیرضروری در تکمیل پروژه بپرهیزند.
۳) تعهد کابران کسبوکار به کاربرد منظم مدلها: علم داده صرفاً نوعی تمرین فکری نیست. مهمترین جنبهی موفقیت علم داده، تولید ارزش کسبوکار ازطریق بینشهای شدنی و تعهد کاربران کسبوکار به عملکردن به این بینشهاست. این تعهد کاربران کسبوکار، از مشارکت و درکشان از فرایند ساخت مدل نشأت میگیرد. دانشمندان علم داده باید رابطهی خوبی با کابران کسبوکار برقرارکنند تا اعتمادشان را جلب نمایند.
مخلص کلام
در این مقاله، متوجه شدیم که شبکههای عصبی مصنوعی، برای مجموعهدادهی ما کمی بهتر از رگرسیون لجستیک و الگوریتمهای درخت تصمیم عمل میکنند. پیش از پرداختن به ادامهی بخش بعدی این مطالعهی موردیِ دایکه، یعنی برآوردها ازطریق رگرسیون، شبکههای عصبی مصنوعی را در مقالهی بعدی مطرح میکنیم. تا بعد!
[1] Support Vector Machines
[2] Random Forest
[3] Naïve Bayes Classifiers
[4] area under receiver operating curve
[5] Gini coefficient
[6] productionization



