
یک دانشمند و یک هنرمند

چند هفته پیش، وقتی در کوچه پسکوچههای فلورانس، مکان زایش رنسانس، میچرخیدم، نتوانستم از فکر لئونارد داوینچی، بزرگترین علامهی تمام دورانها بیرون بیایم. رزومهی درخشان لئونارد حاوی عناوینی مثل نقاش، مخترع، فیزیکدان، منجم، مهندس، زیستشناس، کالبدشناس، زمینشناس و معمار است؛ شوخی نمیکنم! گربهای باهوش مجبور است کل هفت جانش را عمر کند تا نُه عنوانی که لئونارد در یک طول عمر کسب کرد را بهدست آورد. امروز، ضمن مطرحکردن روشهای تصویرسازی دادهها در این سری مقالات دایکه، همچنانکه از سرزمین هنر و علم عبور میکنیم، باید به عمو لئونارد هم ادای احترام کنیم.
هنر و علم تصویرسازی دادهها
تصویر سازی دادهها، همانطور که قبلاً گفتم، هم هنر و هم علم است. من شخصاً ترجیح میدهم مدت طولانی به دادهها نگاه کنم و پیش از پرداختن به مدلسازی ریاضی دقیق، آنها را بهروشهای مختلفی رسم کنم. ممکن است هنگام مرورکردن کارهنری من که در همهی پستهای این وبلاگ ارائه شده است، متوجه علاقهی وافرم به هنر شده باشید. این نقل قول – یک تصویر به هزاران کلمه میارزد – در تحلیل داده هم واقعیت دارد. اگر روی فاز کاوشگرانهی دادهها، که برای من همهاش راجع به تصویر سازی داده است، وقت کافی نگذارید، مدلهای تجزیهوتحلیل بهشدت اشتباه از آب درمیآیند. اجازه دهید یک مثال مطالعهی موردی به شما ارائه بدهم تا جنبههای تصویر سازی دادهها طی فاز کاوشگرانه را توضیح دهم.
مثال مطالعهی موردی بانکداری – مدیریت ریسک
فرضاً شما مدیر ارشد ریسک ([1]CRO) بانک سیندیکت[2] هستید که ۶۰۸۱۶ وام خودرو در مدت سهماههی بین آوریل-ژوئن ۲۰۱۲ اعطا کرده است. امروز، حدود یک سال و سه ماه از زمان اعطای وامها میگذرد، و شما می توانید با قطعیت بالایی وام گیرنده های قابل اعتماد یا بدحساب رو برچسب گذاری کنید و متوجه نرخ بدحسابی حدود ۲.۵ درصد یا ۱۵۲۴ وام بد از بین ۶۰۸۱۶ وام اعطاشده میشوید.
پیش از پرداختن به تحلیل چندمتغیره و رتبهبندی اعتبار، میخواهید نرخ بدحسابی موجود در چند متغیر تکی را تحلیل کنید. از روی تجربه حدس میزنید که سن وام گیرنده در زمان اعطای وام، عاملی کلیدی تشخیصدهندهای برای وام های بد است. بنابراین، وامها را برمبنای سن وامگیرندگان تقسیمبندی میکنید و جدولی مثل جدول زیر میسازید.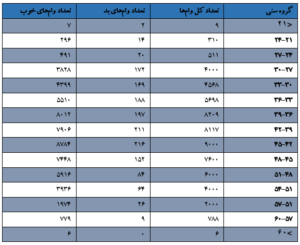 .
.
همانطور که در نمودارهای زیر نشان داده شده است، با استفاده از جدول فوق، هیستوگرامی میسازید و روی ناحیهی موردنظر (نزدیک وامهای بد) زوم میکنید:
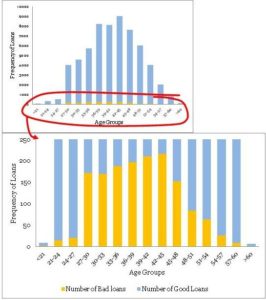
باید متوجه موارد زیر شده باشید:
- توزیع وامها در گروههای سنی، منحنی توزیعشدهی نرمال نسبتاً ملایمی است و بخشهای پرت زیادی ندارد. متغیر سن، اغلب نشاندهندهی همچین الگویی در بیشتر محصولات است. هرچند، منحنیهای مشابهی را برای سایر متغیرهای رایج در سناریو کسبوکار انتظار نداشته باشید. اغلب اوقات، شاید مجبور باشید برای ملایمکردن توزیعها به تبدیل متغیر روی آورید.
- بیشتر وامهای بد در گروه سنی ۴۲ تا ۴۵ سال دیده میشوند. این امر قطعاً بدین معنی نیست که ریسک هم در این باکت سنی (محدوده سنی) بالاترین میزان را دارد، هرچند، یکبار شنیدم کسی در نشستهای بازبینی کسبوکار سهماهه به نتیجهی مشابهی رسیده بود – اشتباهی احمقانه! توجه کنید که بیشتر وامها هم به ۴۲ تا ۴۵ سالهها اعطا شدهاند. اعداد مطلق اطلاعات کافی ارائه نمیدهند، پس باید نموداری نرمال رسم کنیم.
- دادههای مربوط به ردههای جانبی (یعنی، گروههای سنی ۶۰ < و < ۲۱) واقعاً ناچیزند و فقط ۹ و ۶ نقطهی دادهای دارند؛ هنگام کارکردن با چنین دادههای کمی مراقب باشید. دانش کامل کسبوکار برای تعدیل این ردههای جانبی، ضمن توسعهی مدل، بسیار مفید است. برای مثال، میدانید که برای سن بالای ۶۰ سال، وامها میتوانند بسیار پرخطر باشند، اما در این دادهها، شواهد کافی برای اثبات این مسئله نداریم، چرا که دادههای کافی برای تأیید اعتبار فرضیهمان نداریم. در چنین شرایطی، باید وزن ریسک درستی را اضافه کنید؛ هرچند، هنگام انجامدادن چنین چیزی خیلی مراقب باشید.
نمودار نرمال
ترسیم نمودار نرمال آسان است. هدف مقیاسگذاری هر گروه سنی به ۱۰۰ درصد و جایگذاری درصد خوب و بد رکوردها در رأس است. میتوانیم جدول فوق را بسط دهیم تا مقادیر نمودار نرمال را طبق جدول زیر بهدست آوریم: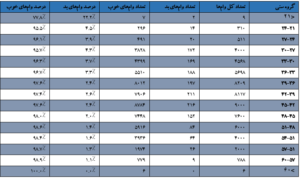
حالا، پس از آمادهسازی جدول، درست همانطور که در زیر نشان داده شده است میتوانید نمودار نرمال را بهسادگی ترسیم کنید (باز هم میگویم که روی نمودار زوم میکنیم تا تصویر واضحی از نرخهای بد بهدست آوریم).
این نمودارها کاملاً با نمودار شمارش فراوانی اولیه فرق دارند و اطلاعات را بهصورت کاملاً متفاوتی ارائه میدهند. موارد زیر، نتایجی هستند که ممکن است از این نمودارها کسب کنید:
- روند قطعیای در رابطه با نرخهای بد و گروههای سنی وجود دارد. با افزایش سن وامگیرندگان، احتمال نکول وام توسط آنها کمتر میشود. این بینش خوبی است.
- باز هم یادآوری میکنم که ردههای حاشیهای یا جانبی (یعنی، گروههای سنی ۶۰ < و < ۲۱) دادههای ناچیزی دارند؛ این اطلاعات را نمیتوان از نمودار نرمال کسب کرد. بنابراین، باید نمودار فراوانی دم دستتان باشد تا بهشیوهی متفاوتی با دادههای کم کار کنید. یکی از قوانین مفید داشتن دستکم ۱۰ رکورد از موارد (خوب و بد)، پیش از رسیدگی جدی به اطلاعات است، وگرنه این اطلاعات از لحاظ آماری معنیدار محسوب نمیشوند.
باید نتیجهگیری کنم که تصویرسازی دادهها سرآغاز فرایند مدلسازی است، نه مقصد. هرچند، این نتیجهگیری شروع خوب و خلاقانهای است.
مخلص کلام
با بهرهگیری از دادههای بزرگ، ابزارها و فناوریهای تحلیل دادهها، پیشرفت علم و محیط دموکراتیک، میتوانستیم در رنسانس عصر خودمان زندگی کنیم. هرچند، به لئونارد داوینچیهای بیشتری نیاز داریم تا بتوانیم این اعصار را واقعاً منحصربهفرد کنیم.