
بخش حاضر ادامهی مطالعهی موردی بانکداریمان برای توسعهی کارتهای امتیاز است. در این بخش، راجع به ارزش اطلاعات (IV)[1]و وزن شواهد بحث میکنیم. این مفاهیم در انتخاب متغیر هنگام توسعهی کارتهای امتیاز اعتباری بهدرد میخوردند. همچنین، نحوهی استفاده از وزن شواهد ([2]WOE) در مدلسازی رگرسیون لجستیک را یاد میگیریم. برای مطالعهی بخشهای قبلی میتوانید به لینکهای بخش ۱، بخش ۲ و بخش ۳ مراجعه کنید.
متخصصینی با کت و شلوارهای گرانقیمت
چند هفته پیش داشتم نمایشی بهنام «بازیهای فکری[3]» را روی کانال نشنال جئوگرافیک[4] تماشا میکردم. در یکی از قسمتها، کمدینی اجرا میکرد که مثل گزارشگر اخبار تلوزیونی لباس پوشیده بود. عوامل دوربین کاملی همراه این کمدین بود. او به مردمی که از پاساژی در کالیفرنیا بیرون میآمدند اطلاع میداد که تگزاس تصمیم گرفته است کشوری مستقل تشکیل دهد و دیگر بخشی از ایالات متحده نباشد. بهعلاوه، روی دوربین نظر مردم راجع به این موضوع را جویا میشد.
پس از مسخرهبازیهای اولیه، مردم او را جدی میگرفتند و شروع به بیان دیدگاههای جدیشان میکردند. این پدیدهای است که روانشناسان بهعنوان «سفسطهی متخصص[5]» یا اطاعت از قدرت حاکم، صرفنظر از اینکه اولیاء امور چقدر غیرمنطقی باشند، توصیف میکنند. مردم پس از فهمیدن حقیقت، در این نمایش تلوزیونی گفتند که حرفهای این کمدین را باور کردند، چون کت و شلوار گرانقیمتی پوشیده بود و عوامل تلوزیونی همراهش داشت.
نیت سیلور[6] در کتابش، «سیگنال و نویز[7]»، پدیدهی مشابهی را توصیف میکند. او پیشبینیهای انجامشده توسط هیئتی از متخصصین در برنامهی تلوزیونی «گروه مکلَفلین[8]» را تحلیل کرد. معلوم شد که این پیشبینیها فقط در ۵۰ درصد موارد واقعیت دارند؛ شما هم میتوانستید با پرتاب سکه همین پیشگویی را بکنید. ما متخصصینی که کت و شلوار گران میپوشند را جدی میگیریم، نه؟ اینها مثالهای مربوط به یکی دو نفر نیستند. مردان کت و شلوارپوش یا یونیفورمپوش در فرمهای مختلفی – از ژنرالهای ارتش گرفته تا نگهبانهای امنیتی پاساژها – ظاهر میشوند. همهی اینها را خیلی جدی میگیریم.
همین الان کشف کردیم که بهجای پذیرش نظر متخصص، بهتر است ارزش اطلاعات را بررسی کنیم و خودمان تصمیم بگیریم. اجازه دهید موضوع را ادامه دهیم و سعی کنیم نحوهی انتساب مقدار به اطلاعات را با استفاده از ارزش اطلاعات و وزن شواهد بررسی کنیم. سپس، با استفاده از WOE (وزن شواهد)، مدل رگرسیون لجستیکی میسازیم. هرچند، پیش از این کار، بیایید به مطالعهی موردیمان برگردیم…
ادامهی مطالعهی موردی…
این بخش ادامهی مطالعهی موردیمان روی بانک سیندیکت است. این بانک ۶۰۸۱۶ وام خودرو با حدود ۲.۵ درصد نرخ بد در سهماههی بین آوریل-ژوئن ۲۰۱۲ اعطا کرده بود. ما با استفاده از تصویرسازی دادهها در دو بخش اول (بخش ۱ و بخش۲)، چند تحلیل کاوشگرانهی داده (EDA) انجام دادیم. در مقالهی قبلی، مدل رگرسیون لجستیک سادهای با متغیر سن (بخش ۳) ساختیم. اینبار، از بخش پایانی مقالهی قبلی مبحث را ادامه میدهیم و از وزن شواهد (WOE) سن برای توسعهی مدل جدید استفاده میکنیم. بهعلاوه، قدرت پیشگویانه متغیر (سن) را ازطریق ارزش اطلاعات بررسی میکنیم.
ارزش اطلاعات (IV) و وزن شواهد (WOE)
ارزش اطلاعات مفهوم بسیار مفیدی در انتخاب متغیر طی ساخت مدل است. فکر میکنم منشأ ارزش اطلاعات، نظریهی اطلاعات پیشنهادشده توسط کلاوده شانون است. دلیلش هم شباهت ارزش اطلاعات با مفهوم پرکاربرد آنتروپی در نظریهی اطلاعات است. مقدار مربع کای، مقیاس پرکاربردی در آمار، جایگزین خوبی برای IV (ارزش اطلاعات) است. هرچند، IV مقیاس رایج و پرکاربردی در صنعت است. دلیل این امر برخی قوانین بسیار راحت در انتخاب متغیرهای مربوط به IV است؛ همانطور که بعدا در همین مقاله خواهید دید، اینها متغیرهای بسیار مفیدی هستند. فرمول ارزش اطلاعات در زیر ارائه شده است:
مفهوم توزیع خوب/ بد بهزودی، زمانیکه IV را برای مطالعهی موردیمان محاسبه میکنیم روشن میشود. حالا احتمالاً زمان مناسبی برای تعریف وزن شواهد (WOE) است که جزء لگاریتمی ارزش اطلاعات محسوب میشود.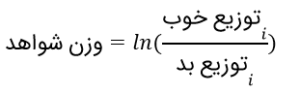
بنابراین، در ادامه میتوان IV را بهصورت زیر نوشت:
اگر هم ارزش اطلاعات و هم وزن شواهد را بهدقت بررسی کنید، پس متوجه خواهید شد زمانیکه یا توزیع خوب یا توزیع بد صفر میشود، هر دوی این مقادیر تجزیه میشوند. یک ریاضیدان از این مسئله متنفر است. فرض، یک فرض درست، این است که این مسئله هنگام توسعهی کارت امتیاز بهدلیل اندازهی منطقی نمونه هیچگاه رخ نمیدهد. احتیاط! اگر کارتهای امتیاز غیراستانداردی با اندازهی نمونهی کوچکتر میسازید، در استفاده از IV دقت کنید.
به مطالعهی موردی برمیگردیم
در مقالهی قبلی، دستههای نادقیقی برای متغیر سن در مطالعهی موردیمان خلق کردیم. حالا، هم ارزش اطلاعات و هم وزن شواهد را برای این دستههای نادقیق حساب میکنیم.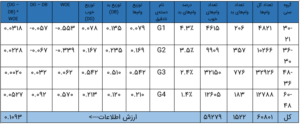
بیایید این جدول را بررسی کنیم. توزیع وامها در اینجا، نسبت وامها دستهی نادقیق به کل وامها است. برای گروه ۳۰-۲۱، این نسبت ۰.۰۷۹ = ۶۰۸۰۱/۴۸۲۱ میشود. همینطور، توزیع بد (DB)، ۱۳۵ = ۱۵۲۲/۲۰۶ و توزیع خوب (DG)، ۰.۰۷۸ = ۵۹۲۷۹/۴۶۱۵ میشود. بهعلاوه، ۰.۰۵۷- = ۰.۱۳۵ – ۰.۰۷۸ = DB – DG. در ادامه، ۰.۵۵۳- = (۰.۱۳۵/۰.۰۷۸)ln = WOE.![]()
نهایتاً، جزء IV این گروه ۰.۰۳۱۸ = (۰.۵۵۳-)*(۰.۰۵۷-) میشود. به همین ترتیب، اجزاء IV سایر دستههای نادقیق را حساب کنید. از افزودن این اجزاء، مقدار IV ۰.۱۰۹۳ (ستون آخر جدول) حاصل میشود. حالا سؤال این است که این مقدار IV را چطور تفسیر کنیم؟ پاسخ قانون سادهایست که در زیر توصیف شده است: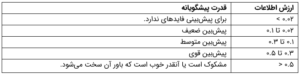
معمولاً متغیرهایی با قدرت پیشگویانهی قوی و متوسط بر ای توسعهی مدل انتخاب میشوند. هرچند، برخی محققان معتقدند که فقط متغیرهایی با IV متوسط باید برای توسعهی مدل مبتنی بر گستردگی استفاده شوند. توجه کنید که ارزش اطلاعات سن، ۰.۱۰۹۳ است، پس بهندرت در محدودهی پیشبینهای متوسط قرار میگیرد.
رگرسیون لجستیک با وزن شواهد (WOE)
در پایان، بیایید مدل رگرسیون لجستیکی با وزن شواهد دستههای نادقیق بهعنوان مقدار متغیر مستقل سن خلق کنیم. جدول زیر، نتایج حاصل از نرمافزاری آماری را ارائه میدهد:
اگر مقدار نرخ بد گروه سنی ۳۰-۲۱ را با استفاده از اطلاعات فوق برآورد کنیم: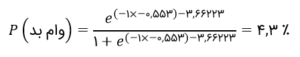
این دقیقاً همان مقداری است که آخرین بار بهدست آوردیم (به بخش قبلی نگاهی بیندازید) و با نرخ بد این گروه سنی سازگار است.
مخلص کلام
آرزو داشتم ابزاری شبیه ارزش اطلاعات وجود داشت تا ارزش اطلاعات ارائهشده توسط این افرادِ بهاصطلاح متخصص را برآورد کنیم. هرچند، دفعهی بعد، وقتی متخصصی در کانال کسبوکار پیشنهاد خرید سهام خاصی را به شما میدهد، خیلی حرف او را باور نکنید.
[3] Brain Games
[4] National Geographic
[5] expert fallacy
[6] Nate Silver
[7] The Signal and The Noise
[8] The McLaughlin Group